** 한국항공대학교 [카카오엔터테인먼트 개발자가 알려주는 백엔드 프로그래밍 특강] 을 참고하여 작성한 post입니다.
백엔드 엔지니어링이란 ?
특강을 듣기 전까지 내가 알고 있던 백엔드 엔지니어링이란
"프론트엔드는 아니고,,, db를 다루며,,, 서버를 다루는,,,기술,,개발,,? " 정도 였다.
백엔드 엔지니어링을 진로로 선택했지만 사실 정확히 그 분야가 어떤 엔지니어링을 하는지 정확히 알기 어려웠다.
특강을 계기로 그 분야에 대해 세부적으로 알 수 있었고 그 부분에 대해 설명하고자 한다.

일단 용어 설명부터 하고 시작하겠다.
LB (Load Balancer)
트래픽이 몰릴 경우를 대비하여 여러 대의 서버로 일을 분산하여 처리해주는 서비스
사용자가 인터넷을 사용할 때는
실상 웹서버를 통해 database를 거쳐 원하는 결과를 응답받는다.
사용자가 1명일때는 웹 서버에 몰리지 않아 빠르게 응답받을 수 있지만 , 만약 사용자가 많아질 경우라면 ?
웹서버는 많아진 사용자를 감당하지 못하고 응답률이 떨어지게 될 것이다.
이런 현상을 예측하고 막기 위한 서비스가 바로 load balancer 이다.
주로 서비스를 성공적으로 배포한 뒤, 사용자가 점차 몰리게 될 때 이런 문제를 겪을 수 있으며,
주로 "서비스 인프라"팀에서 이런 문제를 처리한다.
인프라 확장 방식으로는 scale up 과 scale out이 있다.
scale up
기존 서버보다 성능을 upgrade하는 방법

example
성능 용량 증가, cpu 메모리 업그레이드 등등
쉽게 생각하면, AWS의 EC2 인스턴스를 micro -> small -> medium 등으로 올려 나가는 과정을 칭한다.
실제로, 웹프로젝트<TEAMVIL>의 백엔드개발자로 참여할 때, 개발자들 간의 동시 개발을 위해 EC2 인스턴스를 점차 키워나갔던 경험이 있다.
cost
당연히, 성능이 올라감에 따라 비용 폭이 크게 증가한다.
scale out
서버를 여러대 추가하여 확장하는 방법
이전 1개의 서버가 한계에 도달하면, 비슷한 서버를 추가 연결하여 일을 각 서버에 분담하는 방법이다.
cost
scale up보다 비용부담이 적다.
DB (DataBase)
데이터들의 종합체,모임
사용자가 웹 서버를 통해 일을 요청할 때, 웹은 DB에서 데이터를 가져와 요청한 데이터를 제공해준다.
DB는 디스크에 존재하고, 디스크는 용량이 매우 큰 저장 장소이지만, 속도가 느린 저장 장소이다.
왜 DB를 사용할까 ?
이유야 간단하다. 우리는 책상에 널부러진 책들을 찾는 것보다, 책장에 꽂혀진 책들을 찾기 더 쉬워한다.
즉, DB를 통해 데이터를 구조화하여 사용자의 요청에 더 빠르게 응답할 수 있게 된다.
또한, 데이터는 프로그래밍에 필수적인 요소이다.
데이터 1개라도 사라질 경우, 해당 프로그램은 완전하게 돌아가지 않기 때문에 안전하게 보관하는 것이 필수적이다.
DB는 scale up 방식을 채택한다.
만약, DB가 scale out 방식을 사용한다면 sync의 문제가 발생할 것이다.
새로운 서버를 연결하는데에 매우 짧은 시간이 들겠지만,
그 짧은 시간동안 데이터를 제대로 보내지 못할 경우 문제가 생길 가능성이 크다.
그러므로 DB는 비용 문제를 감당하면서도 scale up방식을 사용한다.
CACHE
자주 사용하는 데이터를 저장해 놓는 임시 저장소
컴퓨터구조론에서 배웠던 정의로는
"CPU와 메모리 사이의 속도 차이를 줄이기 위한 고속메모리" 이다.
이번 포스팅에선, 서버 관점에서 간단하게 설명하고 넘어가겠다.
사용자가 반복적으로 요청하는 데이터 또는 값이 있다고 가정한다.
만약, CACHE가 없고 DB만 존재할 경우, 계속해서 DB에 데이터를 요청해야한다.
상대적으로 DB에는 수많은 데이터가 저장되어있는데
반복적으로 똑같은 데이터를 요청한다면 서버 트래픽을 낭비하게 된다.
또한, 사용자 입장에서는 자주 요청했던 데이터라면 더 빠르게 결과를 응답받기를 원할것이다.
그렇기 때문에 자주 사용되는 데이터는 임시적으로 보관되고, 빠르게 접근 가능한 CACHE에 저장을 한다.
*DB와 CACHE의 구체적인 관계는 추가 포스팅을 업로드 예정이다.
MSA (Micro Service Architecture)
Micro Service 는 말 그대로 작고 독립적인 서비스 각각을 의미한다.
이에 Architecture가 추가되어 "단일 프로그램을 각 컴포넌트 별로 나누어 서비스 조합으로 구축하는 방법"이다.
설명이 어렵다. 좀 더 쉽게 생각해보자.
원래 애플리케이션은 단일의 큰 애플리케이션이었다. 이를 Monolithic Architecutre이라 한다.
애플리케이션의 모든 구성요소가 하나의 프로젝트에 종합되어 있는 형태이다.
개발초기에는 확실히, 단순한 Monolithic Architecture를 선호할 것이다.
하지만, 프로젝트의 규모가 점차 커질 수록 모든 구성요소가 통합되어 있다면
- 구동 시간이 늘어날 것이고
- 수정사항을 위해 전체를 다시 빌드해야하고
- 일부 오류가 전체에 영향을 미칠 것이다.
이를 해결하기 위해 고안한 방법인 Micro Service Architeture이다.
하나의 큰 애플리케이션을 여러 개의 작은 애플리케이션으로 쪼개서 관리하는 방법이다.
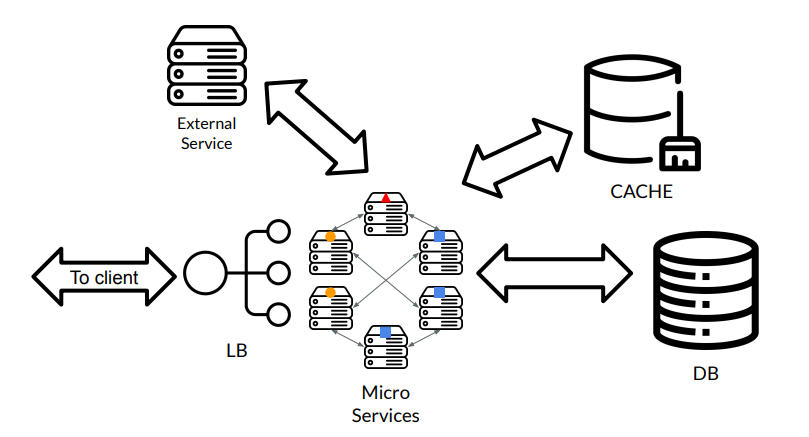
용어를 모두 살펴본 뒤 다시 구조를 확인해보자.
- 클라이언트가 웹에 서비스를 요청한다.
- LB(load balancer)가 가용성에 따라 어느 웹 서버로 보낼지 결정한다.
- 현재 웹은 MSA구조로 각 요청 서비스를 나눠서 응답하기로 한다.
- 캐싱(CACHE)된 데이터가 있다면, DB로 가지 않고 바로 데이터를 반환한다.
- 캐싱(CACHE)된 데이터가 없다면, DB로 가서 요청된 데이터를 반환하면서 캐시에 데이터를 저장한다.
이러한 과정을 다루는 것이 "백엔드 엔지니어링"이다.
'BACKEND > KAU BACKEND 특강' 카테고리의 다른 글
| Spring Persistence (영속성) (0) | 2023.02.03 |
|---|---|
| 스프링 프레임워크 (0) | 2023.01.27 |
| 웹 프로그래밍이란? (0) | 2023.01.20 |