🔗 참고자료
[SQL] Index(인덱스)Index는 RDBMS에서 검색 속도를 높이기 위한 기술이다.TABLE의 컬럼을 색인화(따로 파일로 저장)하여 검색시 해당 TABLE의 레코드를 Full Scan 하는게 아니라 색인화 되어있는 INDEX 파일을 검색하여 검색속도를 빠르게 한다.RDBMS에서 사용하는 I https://velog.io/@gillog/SQL-Index인덱스
https://velog.io/@gillog/SQL-Index인덱스 [MySQL] B-tree, B+tree란? (인덱스와 연관지어서)B-tree는 인덱스를 이루고 있는 자료구조의 일종이다. B-tree에서 'B'는 정확히 어떤 의미라고 밝혀진 바는 없다. 아마 'Balanced'를 의미하는 'B'가 아닐까라는 추측만 있다. MySQL의 DB engine인 InnoDB는 B+tree로 이뤄져있는데, B-tree의 확장된 개념이다. 먼저 B-tree를 살펴보자. 트리 구조의 우위성 트리 구조는 꼭 데이터베이스에 한정하지 않더라도 시스템 세계에서는 데이터를 유지하기 위해 자주 사용하는 구조이다. '탐색' 시, 단시간 내에 실행할 수 있기 때문이다. B-tree의 핵심은 데이터가 정렬된 상태로 유지되어 있다는 것이다. 그림에 표시된 사각형으로 표시된 한 개 한 개의 데이터를 '노드(Node)'라고 한다. 가장 상단의 노드를 '루트 노드(Ro..
[MySQL] B-tree, B+tree란? (인덱스와 연관지어서)B-tree는 인덱스를 이루고 있는 자료구조의 일종이다. B-tree에서 'B'는 정확히 어떤 의미라고 밝혀진 바는 없다. 아마 'Balanced'를 의미하는 'B'가 아닐까라는 추측만 있다. MySQL의 DB engine인 InnoDB는 B+tree로 이뤄져있는데, B-tree의 확장된 개념이다. 먼저 B-tree를 살펴보자. 트리 구조의 우위성 트리 구조는 꼭 데이터베이스에 한정하지 않더라도 시스템 세계에서는 데이터를 유지하기 위해 자주 사용하는 구조이다. '탐색' 시, 단시간 내에 실행할 수 있기 때문이다. B-tree의 핵심은 데이터가 정렬된 상태로 유지되어 있다는 것이다. 그림에 표시된 사각형으로 표시된 한 개 한 개의 데이터를 '노드(Node)'라고 한다. 가장 상단의 노드를 '루트 노드(Ro..https://zorba91.tistory.com/293
 [기술면접] CS 기술면접 질문 - 데이터베이스 (6/8)6. 데이터베이스 [ 인덱스(index)란? ] 인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 만약 우리가 책에서 원하는 내용을 찾는다고 하면, 책의 모든 페이지를 찾아 보는것은 오랜 시간이 걸린다. 그렇기 때문에 책의 저자들은 책의 맨 앞 또는 맨 뒤에 색인을 추가하는데, 데이터베이스의 index는 책의 색인과 같다. 데이터베이스에서도 테이블의 모든 데이터를 검색하면 시간이 오래 걸리기 때문에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 돕고 있다. 만약 Index를 적용하지 않은 컬럼을 조회한다면, 전체를 탐색하는 Full Scan이 수행된다. Full Scan은 전체를 비교하여 탐색하기 때문에 처리..
[기술면접] CS 기술면접 질문 - 데이터베이스 (6/8)6. 데이터베이스 [ 인덱스(index)란? ] 인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 만약 우리가 책에서 원하는 내용을 찾는다고 하면, 책의 모든 페이지를 찾아 보는것은 오랜 시간이 걸린다. 그렇기 때문에 책의 저자들은 책의 맨 앞 또는 맨 뒤에 색인을 추가하는데, 데이터베이스의 index는 책의 색인과 같다. 데이터베이스에서도 테이블의 모든 데이터를 검색하면 시간이 오래 걸리기 때문에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 돕고 있다. 만약 Index를 적용하지 않은 컬럼을 조회한다면, 전체를 탐색하는 Full Scan이 수행된다. Full Scan은 전체를 비교하여 탐색하기 때문에 처리.. DataBase Index에서 기본적으로 HashTable이 아닌 B-Tree를 쓰는 이유의문의 시작 해시 테이블은 삽입, 삭제, 탐색 시 평균적으로 O(1)의 시간복잡도를 가지는 좋은 성능의 자료구조인데 DateBase에서 Index로 사용안하는지 갑자기 의문이 생겼다. 지금 생각해보면 조금만 고민하면 답을 찾을 수 있는데 왜 안보였는지... 서치를 해보니 나와 같은 의문점을 가진 사람들이 꽤 있어서 자료가 찾기 편했다. 바로 알아보자! 자료구조 비교 HashTable HashTable이란 Key와 Value로 데이터를 저장하는 자료구조 중 하나로써, 데이터의 삽입, 삭제, 탐색에 평균적으로 O(1)이라는 빠른 성능의 시간복잡도를 자랑하는 자료구조이다. HashTable의 프로세스를 알아보면, 검색하고자 하는 키값을 입력받아서 해시함수를 통해 반환받은 HashCode를 배열의 Index로 ..
DataBase Index에서 기본적으로 HashTable이 아닌 B-Tree를 쓰는 이유의문의 시작 해시 테이블은 삽입, 삭제, 탐색 시 평균적으로 O(1)의 시간복잡도를 가지는 좋은 성능의 자료구조인데 DateBase에서 Index로 사용안하는지 갑자기 의문이 생겼다. 지금 생각해보면 조금만 고민하면 답을 찾을 수 있는데 왜 안보였는지... 서치를 해보니 나와 같은 의문점을 가진 사람들이 꽤 있어서 자료가 찾기 편했다. 바로 알아보자! 자료구조 비교 HashTable HashTable이란 Key와 Value로 데이터를 저장하는 자료구조 중 하나로써, 데이터의 삽입, 삭제, 탐색에 평균적으로 O(1)이라는 빠른 성능의 시간복잡도를 자랑하는 자료구조이다. HashTable의 프로세스를 알아보면, 검색하고자 하는 키값을 입력받아서 해시함수를 통해 반환받은 HashCode를 배열의 Index로 ..
인덱스란?
추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블(RDBMS)의 검색 속도를 향상시키기 위한 자료구조
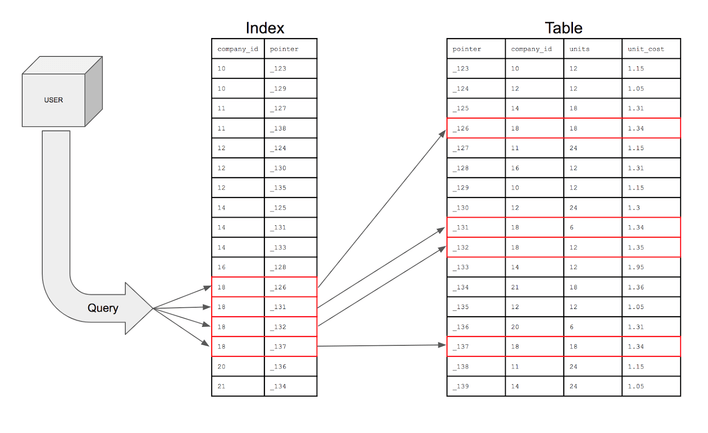
왜 Index를 사용하는가?
- 특정 기준(Where구문과 일치하는) 맞는 rows를 빠르게 찾기 위해서 사용
└ Table의 컬럼을 색인화(따로 파일로 저장)하여 검색시, 해당 Table의 데이터를 Full-Scan하지 않고, 인덱스 파일만을 검색하여 검색 속도를 up
- 특정 열을 고려 대상에서 빨리 없애기 위해
- Join을 실행할 때, 다른 테이블에서 열을 추출하기 위해
- 쿼리를 최적화하는 경우
Index의 장단점
- 장점
- 키 값을 기초로 하여 검색과 정렬 속도를 향상
- 그룹화 작업의 속도를 향상
- 테이블 행의 고유성을 강화
- 테이블의 pk는 자동으로 인덱스가 됨
- 단점
- 인덱스를 관리하는 비용 발생
- 인덱스를 저장하기 위한 space 사용 증가
- 만약 index를 쓰지 않는다면 ? Full Scan을 수행해야함 = 처리 속도 매우 느려짐
- 데이터 변경 작업이 자주 일어날 경우, 계속해서 재작성해아 하므로, 성능에 오히려 악영향
└ 데이터 변경 ,추가, 삭제 == 성능 악화
정답은 No. 남발하면 안된다.
DB 서버에 성능 문제가 발생하면 가장 빨리 해결할 수 있는 방법은 인덱스 추가이다.
계속해서 인덱스를 생성하게 되면, 하나의 쿼리문을 빠르게 만들수는 있지만, 전반적으로 봤을 때 데이터베이스의 성능을 악화시키는 꼴이다.
구체적으로, 조회 성능을 극대화하려고 인덱스를 쓰는 건데, 오히려 Insert, Delete, Update 하는 시간이 오래 걸려서 db 조회가 오래 걸리는 문제가 발생할 수 있는 것이다.
∵ 인덱스를 생성하는 것보다, SQL문을 처음부터 효과적으로 짜는 방향이 best
Index의 구조
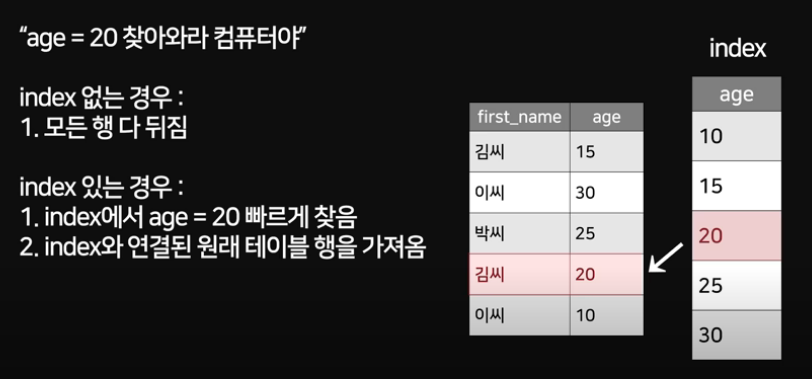
** Index는 RDB의 테이블과 논리적/물리적으로 독립적!
└ RDB 테이블은 정렬X, 입력순서대로 || Index는 key컬럼과 RowId컬럼 2개로 이뤄져 정렬 가능
** 디스크 공간은 보통 테이블을 저장하는데 필요한 디스크 공간보단 작다
└ RDB처럼 테이블의 세부항목을 모두 갖지 않고 Key와 ROWID만 갖기 때문
ROWID : row(행-가로)를 식별하기 위해 갖는 물리적인 주소 정보
- Search Key
index에서 검색하기 위해 사용되는 column 또는 column의 집합
한 테이블에서 다른 search key를 갖는 다수의 index가 생성 가능해짐
- Files
MySQL에서 테이블 생성시, 3가지 파일이 생성됨
- FRM : 테이블 구조 저장 파일
- MYD : 실제 데이터 파일
- MYI : Index 정보 파일
└ 쿼리를 이용하여 Index를 사용하는 column을 검색시, MYI 파일의 내용을 활용함
Index 작동 원리
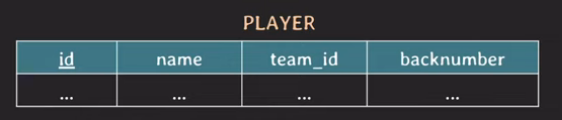
- 이미 사용하고 있는 RDB에 INDEX를 걸어주는 방법
SELECT * FROM player WHERE name = 'Sonny';
SELECT * FROM player WHERE team_id = 105 and backnumber = 7;
/**(1) name에 index를 걸기**/
CREATE INDEX player_name_idx ON player(name);
//name은 중복이 있을 수 있으므로 player테이블의 name attribute에 대해서 index를 만들기
/**(2) team_id와 backnumber 에 index를 걸기**/
CREATE UNIQUE INDEX team_id_backnumber_idx ON player(team_id,backnumber);
// └ multicolumn index(composite index)
- 테이블을 생성하면서 처음부터 INDEX를 걸어주기
create table player (
id INT PRIMARY KEY, //primary key에는 index가 자동으로 생성됨
name VARCHAR(20) NOT NULL,
team_id INT
backnumber INT
INDEX player_name_idx(name),
UNIQUE INDEX team_id_backnumber_idx(team_id,backnumber)
// └ multicolumn index(composite index)
);
- 인덱스 정보들을 알고싶을 경우
SHOW INDEX FROM player;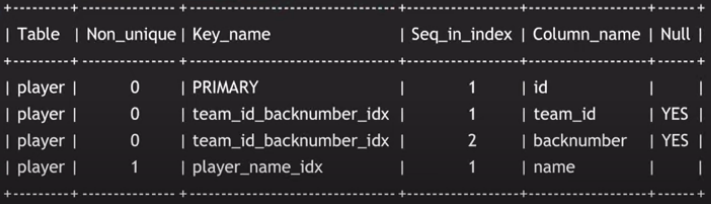
multicolumn index는 seq_in_index가 순차적으로 증가됨 ⇒ column_name으로 attribute 확인하기
인덱스를 만들 때 고려해야할 사항
- 인덱스가 언제 사용될 것인가 ?
- 정확하게 key와 일치하는 row들을 찾을 때 사용할 것인가 ?
- Range Query에 사용하나?
- 테이블에 모든 row들을 조회할 때 사용할 것인가?
- 테이블이 얼마나 자주 업데이트 되는가?
- DML은 index 관리를 위한 update가 발생함
- 인덱스의 key가 super key or primary key?
- 하나의 key로 여려 row들이 가능한가 ? Unique or not
언제 Index를 사용해야할까?
- 규모가 큰 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 칼럼
- JOIN이나, WHERE 또는 ORDER BY에 자주 사용되는 칼럼
- 데이터의 중복도가 낮은 칼럼 (=카디널리티가 높은 칼럼)
[정리VER]
- Cardinality(카디널리티)
✨ 높을수록 인덱스 설정에 좋은 칼럼
(= 한 칼럼이 갖고 있는 값의 중복도가 낮을 수록)
즉, 카디널리티 = 1/중복도
- Selectivity(선택도)
✨ 낮을 수록 인덱스 설정에 좋은 칼럼
= 칼럼의 특정 값의 row 수 / 테이블의 총 row 수 * 100
- 활용도
✨ 활용도가 높을 수록 인덱스 설정에 좋은 칼럼
= WHERE 절에 자주 활용되는지
- 중복도
✨ 중복도가 없을 수록 인덱스 설정에 좋은 칼럼
인덱스의 자료구조
Index 종류
| 분류 | Index 종류 | DEF |
| 유일성 | Unique Index | Index 키는 연관된 테이블의 하나의 행만 가리킴(중복이 없음) |
| Non-Unique Index | Index 키는 연관된 테이블의 여러 행을 가리킴 (중복이 있음) | |
| 구성 컬럼 수 | Single Index | 하나의 column으로 구성된 Index |
| Composite Index | 여러개의 column으로 구성된 Index(32개까지) | |
| 클러스터 | Clustered Index | 데이터의 순서가 Index 페이지의 정렬순서와 동일 ⇒ 한 테이블에 중복을 허용하지 않음 ⇒ Order By를 사용하지 않아도, 데이터가 정렬되있으므로 가장 빠른 처리 ⇒ 기본적으로 PK INDEX는 Clustered Index |
| Non-Clustered Index | 데이터의 순서가 Index 페이지와 상관없이 저장 | |
| 함수 | Function-Based Index | 함수 or 표현식의 계산값으로 인덱스 생성 |
| 기타 | Bitmap Index | 비트를 이용하여 칼럼값을 저장, rowID를 자동으로 생성 |
| Reverse key Index | Index칼럼의 순서는 유지, 해당 column값의 각 바이트 위치를 거꾸로 저장 |
Hash Table
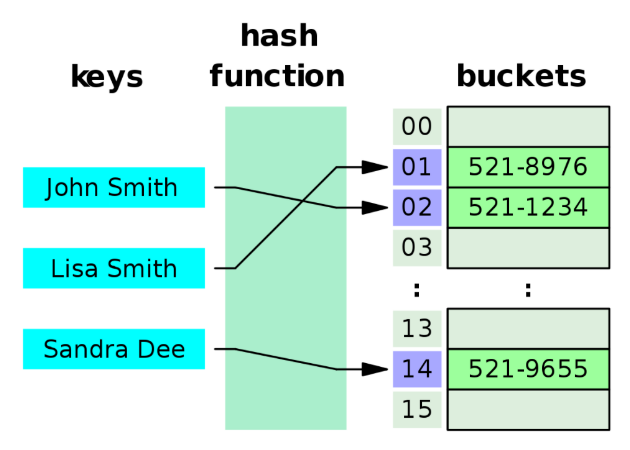
- 칼럼 값으로 생성된 해시를 기반으로 인덱스를 구현
└ 값을 변형해서 인덱싱하므로, 특정 문자로 시작하는 값으로 검색하는 등 값의 일부만으로 검색하므로할 때는 해시 인덱스 사용 불가능 !! ⇒ 메모리 기반의 데이터베이스에서 많이 사용
Process
- 검색하고자 하는 키 값을 입력받음
- 해시 함수를 통해 HashCode 반환
- 배열의 Index로 환산
- Value에 접근
장점
- 시간복잡도 : O(1) : 검색용이
문제점
- 부등호(>,<)와 같은 연속적인 데이터를 위한 순차 검색은 X
- 해시 충돌
- 키 값은 무한대지만, HashCode는 정수개로 한정되기에 중복되는 HashCode를 갖는 충돌발생
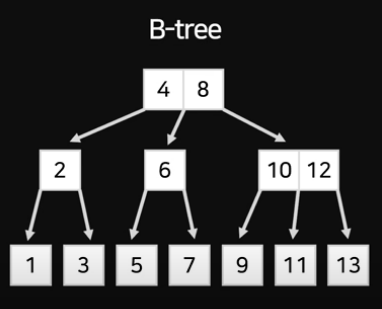
B-Tree
**여기서 B : Balanced ⇒ 한쪽으로 쏠리지 않도록 트리가 재정렬됨
B+Tree
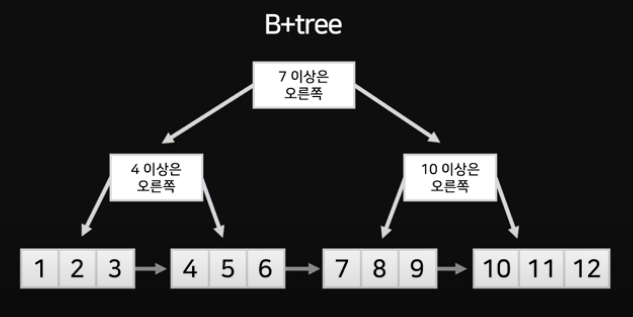
- 자식 노드가 2개 이상 (B-Tree를 개선시킨 자료구조)
- 데이터는 맨 밑의 노드들만 보관하고, 위에는 가이드만 제공한다
- B-Tree의 리프노드들을 LinkedList로 연결하여 순차 검색을 용이하게 함 (⇒ 범위검색이 매우 쉬워짐)
- 해시 테이블보단 O()의 시간복잡도를 갖지만, 더 흔하게 사용됨
| 구분 | B-Tree | B+Tree |
| 데이터 저장 | 리프노드, 브랜치 노드 모두 데이터 저장 | 오직 리프 노드에만 데이터 저장 |
| 트리의 높이 | 높음 | 낮음 ⇒ 한 노드 당 key를 많이 담을 수 있음 |
| 풀 스캔시, 검색 속도 | 모든 노드 탐색 | 리프 노드에서 선형탐색 |
| 키 중복 | X | O ⇒ 리프 노드에 모든 데이터가 있기에 |
| 검색 | - 자주 access되는 노드 : 루트노드 근처 └ 브랜치 노드에도 데이터가 존재하기에 빠름 | 리프노드 까지 가야 데이터가 존재 |
| LinkedList | x | 리프 노드끼리 LinkedList로 연결 |
- 해시테이블은 동등연산(=)에 특화되어 있어서 데이터베이스의 자료구조에 적합하지 않다.
- 해시테이블에 저장되는 값들을 정렬되어 있지 않기에 특정 값보다 크거나, 작은 값(>,<)을 찾을 수 없다.
∵ SQL 쿼리문에서 특정 범위의 값을 조회하는 경우, 특정 값보다 크거나, 작은 값을 찾을 수 없다.
- 반대로 B+Tree는 SELECT를 할 때, =, >, <처럼 모든 범위탐색도 가능
- 노드마다 배열로 구현되어 있기 때문에 방대한 데이터 접근이 가능하다 .
Index로는 부적합하지만, Join하는 경우(’=연산자’ 사용)에 사용된다.
적은 데이터의 테이블을 메모리에 HashTable로 올려두고, HashJoin을 사용할 때 빠르게 조회할 수 o
Uploaded by N2T